Gravitas Automated Grading
A final-year research project combining Optical Mark Recognition and transformer-based NLP to automate grading of both multiple-choice and short answer questions.
Overview
Final-year research project, completed at the University of Nottingham Malaysia. The system tackles two distinct grading problems under one roof: an Automated Short Answer Grading (ASAG) pipeline for free-text responses, and an Optical Mark Recognition (OMR) subsystem for multiple-choice questions.
The NLP side goes beyond simple keyword matching; it orchestrates three model families (STS, NER, and LLM) whose weaknesses offset each other to produce a final score. The OMR side is entirely software-based, with no proprietary scanning hardware required. Any institution with a photocopier can run it.
What it does
- Grades short answers (50–100 words) against reference answers using a fine-tuned RoBERTa cross-encoder.
- Runs a Multi STS Ensembled model that combines RoBERTa, GIST Embedding, and MiniLM through a dense fusion layer.
- Extracts and normalizes physical quantities (e.g. kg cm⁻³ → kg m⁻³) using a GloVe-based NER model, catching numerical errors that semantic similarity alone misses.
- Integrates Llama 3 70B via zero-shot prompting to generate per-student written feedback, batching answers by question to minimize token cost.
- Serves all NLP models through NVIDIA Triton Inference Server on Vast.ai at approximately $0.08/hour, with throughput of 317 inferences/second for the STS model on an RTX 3050.
- Processes scanned OMR answer sheets using OpenCV (grayscale conversion, normalization, erosion, perspective transform, and adaptive threshold bubble detection), returning results as a CSV in under 0.5 seconds per sheet.
- Exposes everything through FastAPI endpoints that slot into an existing learning management system, returning bulk-upserted scores to the database in a single round trip.
Stack choices
For ASAG, the backbone is the cross-encoder/stsb-roberta-base model from HuggingFace, fine-tuned for the specific task of reference-answer/student-answer similarity scoring. Training uses BCEWithLogitsLoss, AdamW with decoupled weight decay, and a linear warmup + decay scheduler over 10 epochs with batch size 16. Five-fold cross-validation with a 60-20-20 split is applied across all datasets except those (SciEntsBank, Beetle, ASAP-SAS) that ship with their own held-out test sets.
The ensemble adds Sentence-BERT-style Siamese networks on GIST Embedding and MiniLM alongside the cross-encoder, comparing embeddings via cosine similarity. The outputs feed into a shared dense layer for the final prediction. Transfer learning on the base models meant the ensembling head required very little training; it plateaued at epoch one.
Model optimization uses NVIDIA TensorRT: PyTorch models are first traced to TorchScript (JIT), then compiled inside an NGC Docker container where the TensorRT compiler fuses operations, prunes the computation graph, and selects optimal CUDA kernels per layer. The resulting engines are loaded into Triton, which handles dynamic batching (max batch 8) and concurrent multi-model serving on the same GPU.
The NER component uses GloVe quantulum3 rather than a heavier transformer, a deliberate trade-off: inference speed and deployment cost matter more than raw NER accuracy when the domain is narrow (units, measurements, constants). The quantities Python library handles SI unit normalization, including derived units.
The OMR subsystem is built on top of OMRChecker's image processing pipeline, extended with a custom adaptive thresholding strategy that switches between local and global thresholds depending on whether a confident gap exists in the bubble value distribution. This makes it robust to marks that overspill bubbles or leave faint erasure residues, a real problem with student answer sheets in the field.
Challenges
The Dual-Tasking Fusion Model, which tried to combine STS and QNLI signals to give the grader access to question intent as well as answer similarity, failed to converge. The root cause was a mismatch between the QNLI training signal and the score labels: a wrong answer can still be topically related to the question, which introduces noise that the QNLI pathway couldn't learn through.
Quantity normalization is harder than converting base units. Derived units like kg cm⁻³ require chaining conversion factors across multiple dimensions, and the quantities library handles this automatically, but constructing reliable grounding between the NER output and the normalized comparison still required care to avoid false mismatches on rounding or unit aliasing.
Throughput was uneven across models. The STS model hits 317 inferences/second at batch size 4 on an RTX 3050, where TensorRT optimization worked well. The Multi STS Ensembled model only reached 29 inferences/second at the same batch size, roughly ten times slower despite being only five to six times larger by parameter count. The bottleneck appears to be the Siamese branch architecture, which does not parallelize as cleanly under TensorRT's graph optimization, and may also reflect an implementation issue with how the parallel branches share compute.
The broader design challenge is the score fusion heuristic. Combining three heterogeneous signals (a normalized STS score, a quantity match score, and an LLM-assigned score) into a single grade requires a rule that degrades gracefully when any one model is unreliable. The final logic checks whether the STS score falls below the mean of the NER and LLM scores (indicating possible factual error that the STS model underweighted) and adjusts the weighting accordingly. It is a pragmatic fix rather than a learned one, and the right long-term solution is to train a meta-model on held-out data.
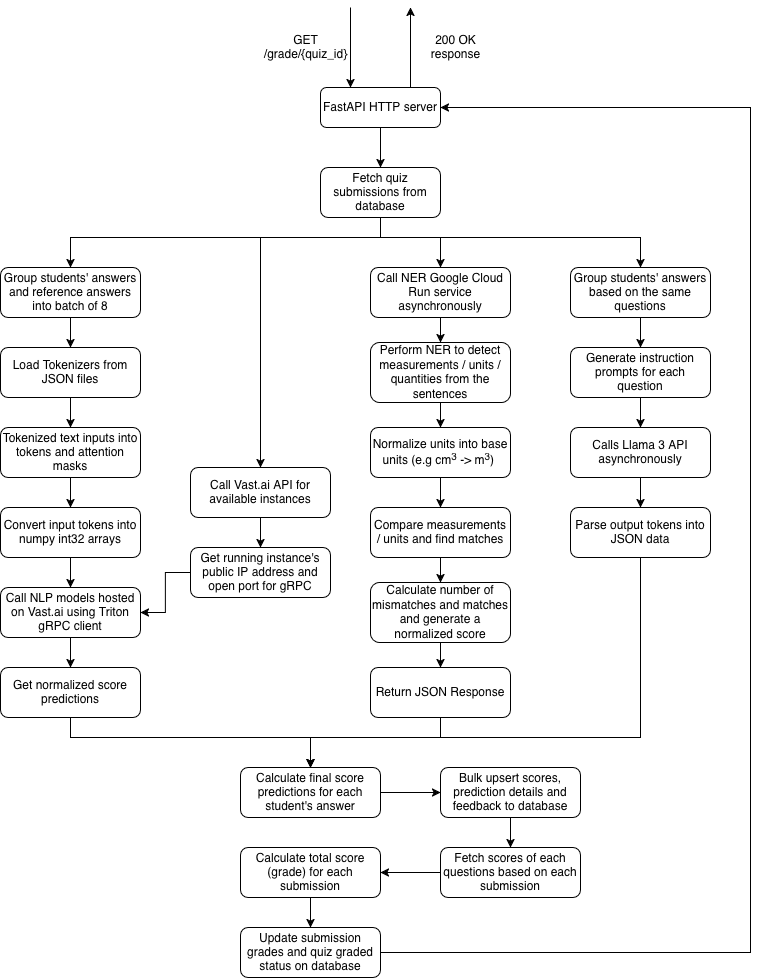 NLP Automated Grading Overview
NLP Automated Grading Overview
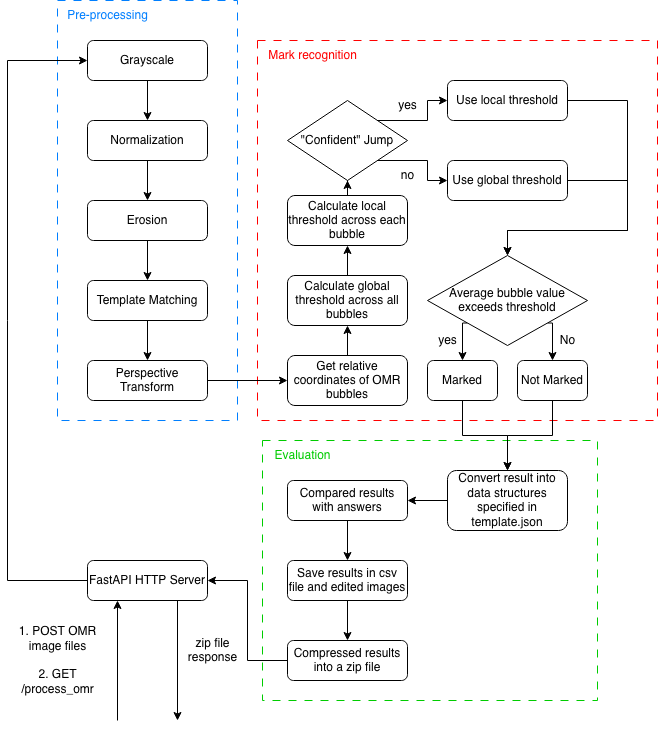 OMR Automated Grading Overview
OMR Automated Grading Overview